
Как работает инструмент RESTler: продвинутый фаззинг REST API для поиска уязвимостей
Современные веб-сервисы становятся всё сложнее, и обычные тесты часто не способны выявить скрытые ошибки в логике работы API. В этой статье мы покажем, как использовать инструмент RESTler для продвинутого фаззинга REST API, чтобы исследовать поведение сервиса в сложных сценариях.
Что такое фаззинг REST API и зачем он нужен
Под фаззингом API понимается метод автоматизированного тестирования интерфейсов приложений. Он проверяет, как система реагирует на некорректные, неожиданные или комбинированные входные данные. Такой подход подходит для любых интерфейсов: веб-сервисов, библиотек, микросервисов, RPC или SOAP.
Инструмент фаззинга выявляет:
- сбои при передаче некорректного формата данных;
- ошибки сериализации/десериализации;
- проблемы с ресурсами или памятью;
- неожиданные ответы при редких комбинациях вызовов функций.
REST API (Representational State Transfer Application Programming Interface) – это тип веб-API, который используется для обмена данными между клиентом и сервером через стандартные HTTP-запросы (GET, POST, PUT, DELETE).
Фаззинг REST API – это частный случай фаззинга API, ориентированный на веб-сервисы в стиле REST. Он имеет несколько особенностей:
1. Сеть и HTTP как среда тестирования.
REST API строится поверх протокола HTTP. Фаззинг здесь работает не с функциями в памяти, а с реальными HTTP-запросами и ответами, что добавляет сложности: нужно учитывать коды статуса, заголовки, методы, параметры в URL и тело запроса в формате JSON.
2. Ресурсы и состояние.
В REST каждый эндпоинт оперирует ресурсами. Например, чтобы получить доступ к книге пользователя, сначала нужно её создать и авторизоваться. Фаззинг REST API должен строить цепочки запросов с учетом зависимостей между ресурсами, иначе многие сценарии останутся не протестированными.
3. Авторизация и сессии.
REST API почти всегда защищены: нужен токен, куки или ключ API. Фаззер должен динамически работать с авторизацией, иначе проверяются только «пустые» запросы, которые не дают информации о реальных уязвимостях.
4. Логические ошибки бизнес-процессов.
В отличие от низкоуровневого API-фаззинга (например, библиотек), REST API чаще подвержены ошибкам бизнес-логики. Корректный HTTP-ответ может скрывать нарушение правил приложения: повторный платеж, доступ к чужим данным, обход ограничений.
5. Масштаб и покрытие.
REST API обычно имеют десятки эндпоинтов и сложные сценарии использования. Фаззинг REST API требует планирования и генерации последовательностей запросов, чтобы покрыть реальные пути использования сервиса.
Пример:
- Фаззинг обычного API проверяет, не падает ли библиотека при передаче разных значений в функцию
setUserAge(age). - Фаззинг REST API проверяет реальные сценарии: создать пользователя → авторизоваться → попытаться изменить чужой профиль → удалить пользователя → проверить, остались ли связанные данные, при этом корректно обновляя токены и учитывая последовательность вызовов.
Продвинутый анализ REST API с RESTler
RESTler – это stateful REST API фаззер для глубокого тестирования веб-сервисов REST, позволяющий выявлять дефекты и логические уязвимости в сложных сценариях использования. Инструмент разработан командой Microsoft Research, выпущен в 2016 году.
Под фаззером stateful REST API понимается инструмент, который не просто проверяет отдельные эндпоинты, а строит последовательности запросов, учитывая текущее состояние ресурсов, зависимости между ними и требования авторизации.
Ключевые возможности RESTler:
- Автоматическая генерация последовательностей запросов с учётом зависимостей между ресурсами.
- Отслеживание состояния сервера (stateful), что позволяет тестировать сценарии, где порядок вызовов критичен.
- Работа с авторизацией: токены, куки, API-ключи.
- Выявление логических ошибок бизнес-процессов, даже при корректных HTTP-ответах.
- Масштабируемое покрытие десятков эндпоинтов и сложных сценариев.
- Гибкая настройка тестирования: исключение параметров, кастомные коды багов и мутации.
- Сбор и анализ логов для воспроизведения уязвимостей и понимания контекста.
Как провести stateful REST API фаззинг с помощью RESTler
RESTler поддерживает основные операционные системы (Windows, Linux, macOS) и может быть собран как в виде Docker-образа или отдельного бинарного файла. Рассмотрим базовый процесс работы на примере demo-сервера, который поставляется вместе с инструментом.
Компиляция OpenAPI-спецификации
На этом этапе описание OpenAPI переводится в понятный фаззеру формат:
Restler.exe compile --api_spec C:\demo_server\swagger.json
Создается каталог Compile, который содержит файлы:
- grammar.py / grammar.json
Описывают структуру API: параметры запросов, зависимости между ними и правила генерации цепочек. В этом файле задаются механизмы извлечения данных из ответов для использования в последующих запросах. - dict.json
Словарь значений для параметров. Он определяет, какие именно данные будут использоваться при фаззинге. Например, параметры с типомrestler_fuzzable_stringбудут автоматически мутироваться. При необходимости сюда можно добавить собственные значения черезrestler_custom_payload. - config.json
Позволяет настраивать процесс компиляции: подключать дополнительные грамматики или объединять несколько спецификаций. - engine_settings.json
Основной конфигурационный файл фаззера. Здесь задаются параметры запуска: адрес цели, генерация данных, поведение фаззинга и настройки для отдельных эндпоинтов.
Проверка спецификации
После компиляции важно убедиться, что RESTler корректно «понимает» API. Для этого используется тестовый режим:
restler.exe test \
--grammar_file grammar.py \
--dictionary_file dict.json \
--settings engine_settings.json
На этом этапе инструмент пытается выполнить каждый запрос хотя бы один раз и получить корректный ответ.
Результаты сохраняются в каталоге Test/RestlerResults/.../logs, где доступны speccov.json (покрытие спецификации), main.txt (лог выполнения запросов) и network.testing.*.txt (полный HTTP-трафик запросов и ответов). Результаты для всех комбинаций параметров отображаются в файле speccov.json.
Важно понимать, что по умолчанию RESTler проверяет только одну успешную комбинацию параметров. Если требуется перебрать все варианты, используется режим полного покрытия (test_all_combinations).
Быстрый фаззинг: Fuzz-lean
Когда базовое покрытие достигнуто, можно переходить к фаззингу. Так выглядит облегченный вариант:
restler.exe fuzz-lean \
--grammar_file grammar.py \
--dictionary_file dict.json \
--settings engine_settings.json
Этот режим ориентирован на быстрый поиск очевидных проблем. Каждый эндпоинт проверяется ограниченным числом сценариев, что позволяет быстро получить первые результаты.
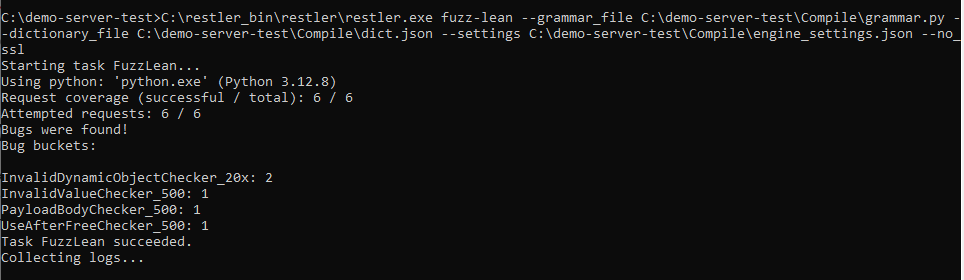
Найденные ошибки сохраняются в каталоге FuzzLean/RestlerResults/..., где появляется дополнительная директория bug_buckets (набор уникальных последовательностей запросов, которые привели к ошибкам).
Ошибки группируются не по отдельным запросам, а по сценариям их выполнения, что значительно упрощает анализ.
Анализ и сортировка уязвимостей
RESTler умеет находить не только сбои (например, HTTP 500), но и более сложные логические проблемы. Для этого используются встроенные механизмы анализа поведения API (чекеры).
Примеры:
- Invalid Dynamic Object
Фаззер модифицирует идентификатор ресурса (например, добавляя неожиданные параметры в URL).
Если сервер принимает такой запрос и возвращает успешный ответ, это считается ошибкой валидации.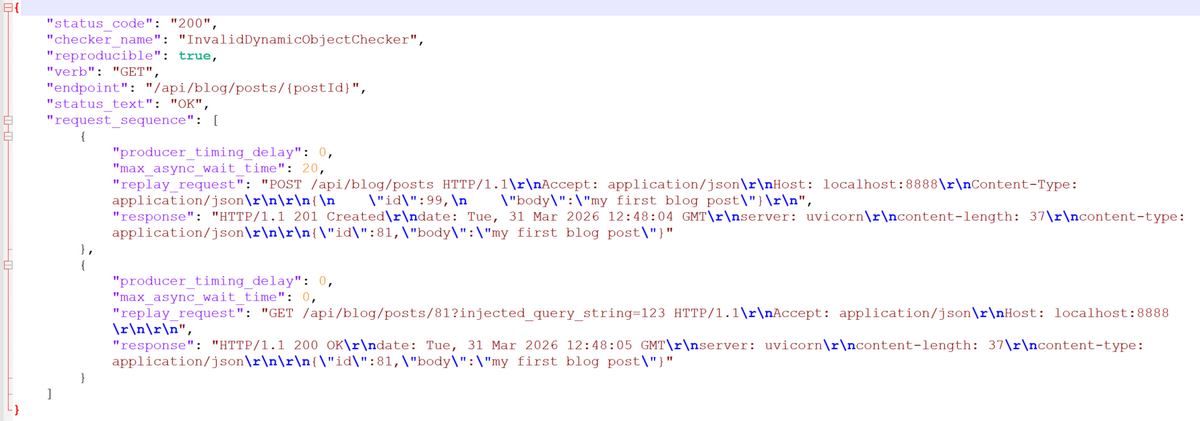
- Use-After-Free
Сценарий:1. Создание ресурса.
2. Удаление ресурса.
3. Попытка повторного доступа.
Если API продолжает возвращать данные, значит ресурс фактически не был удален, что является логической уязвимостью.
Режим Fuzz
Для более глубокого анализа используется режим Fuzz:
restler.exe fuzz \
--grammar_file grammar.py \
--dictionary_file dict.json \
--settings engine_settings.json \
--time_budget 1
Параметр time_budget задает длительность работы (в часах).
В этом режиме RESTler:
- строит более длинные цепочки запросов;
- комбинирует различные сценарии;
- повторно использует найденные зависимости.
Результаты сохраняются в каталоге Fuzz/RestlerResults/....
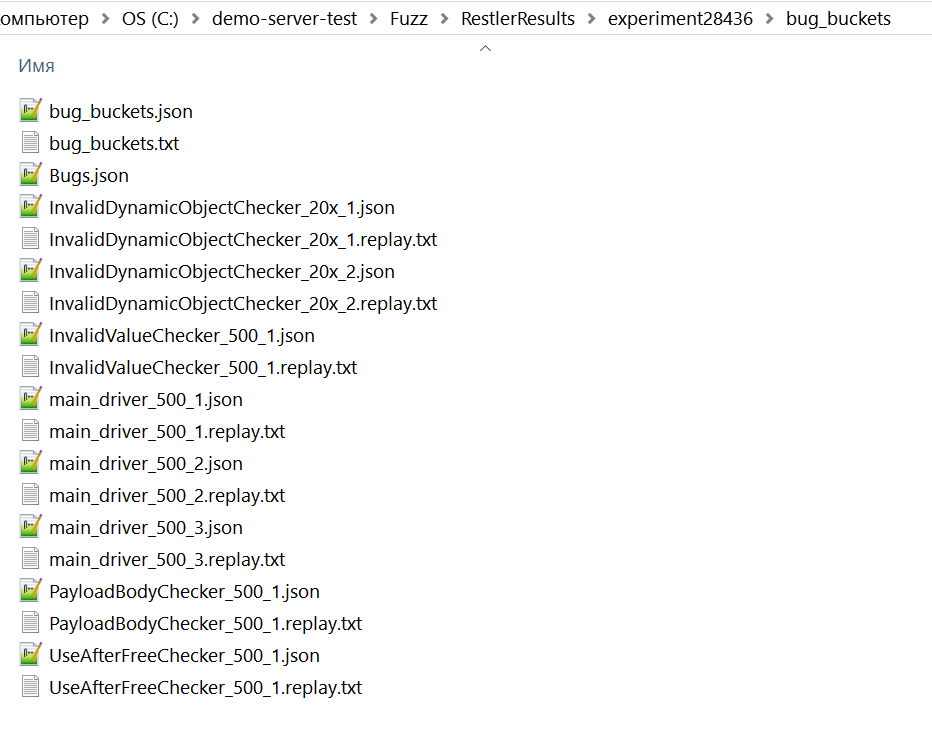
Даже если ошибки повторяются, инструмент группирует их по сценариям и не дублирует, что делает отчеты более удобными для анализа.
Что это дает на практике
Даже на простых API RESTler способен выявить:
- ошибки обработки идентификаторов;
- некорректную работу удаления ресурсов;
- отсутствие валидации входных данных;
- логические уязвимости, связанные с последовательностью действий.
Проверка цепочек запросов и учета состояния системы позволяет исследовать поведение API в рабочих условиях.
Стратегии поиска: как RESTler исследует API
Итак, базовая настройка завершена и фаззер готов к работе. Дальше необходимо определить, каким образом инструмент будет исследовать пространство возможных запросов. От этого напрямую зависит глубина анализа и скорость обнаружения дефектов.
RESTler строит цепочки запросов, постепенно расширяя их и учитывая зависимости между эндпоинтами. При этом он может использовать разные подходы к поиску, каждый из которых по-своему балансирует между полнотой покрытия и производительностью.
Режимы поиска:
Обход в ширину (BFS). В этом режиме фаззер методично наращивает длину цепочек, добавляя новые запросы только тогда, когда для них выполнены все зависимости. Например, если определенный эндпоинт требует идентификатор объекта, RESTler сначала сформирует запрос на его создание, и только затем попытается использовать его в дальнейшем.
На каждом шаге происходит перебор возможных значений параметров, если они объявлены как изменяемые. В результате формируется большое количество комбинаций, каждая из которых проверяется на корректность. Если сервер отвечает так, как ожидается, то цепочка сохраняется и применяется для дальнейшего расширения. Если нет, она отклоняется и фиксируется дефект.
BFS-Fast. В этом сценарии используется метод обхода в ширину с ограничением количества генерируемых последовательностей. Вместо полного перебора каждая операция добавляется лишь к одной подходящей цепочке. Это позволяет быстрее углубляться в сценарии и при этом не терять охват всех эндпоинтов.
Random Walk. Здесь фаззер отказывается от систематического перебора и начинает исследовать API более «интуитивно», случайным образом выбирая как сами запросы, так и цепочки, к которым они добавляются. Такой метод позволяет быстрее находить глубокие и нестандартные сценарии, но не гарантирует полного покрытия. Более того, при каждом запуске исследование начинается заново, и ранее найденные последовательности не переиспользуются.
На практике ни одна из стратегий не является универсальной. Чаще всего их комбинируют: сначала используют более быстрые режимы для грубой разведки, а затем переходят к более полным стратегиям.
Выбор режима можно задать напрямую при запуске:
--search_strategy bfs-fast
или через конфигурационный файл:
{
"fuzzing_mode": "bfs"
}
Аннотации: управление зависимостями вручную
На практике API редко бывают идеально описаны. Часто в спецификации отсутствуют связи между созданием объекта и его последующим использованием. В результате фаззер не может корректно выстроить цепочку и начинает генерировать множество некорректных запросов. Аннотации позволяют решить эту проблему, указывая, какой эндпоинт «производит» данные, а какой их использует. Пример такой связи может выглядеть следующим образом:
{
"producer_endpoint": "/projects",
"producer_method": "POST",
"producer_resource_name": "id",
"consumer_endpoint": "/projects/{id}",
"consumer_method": "GET",
"consumer_param": "id",
"description": "Связь между созданием и получением проекта"
}
После компиляции RESTler начинает автоматически подставлять значения, полученные на предыдущих шагах, в последующие запросы. Это позволяет строить корректные и реалистичные сценарии взаимодействия.
Фактически аннотации превращают фаззер из генератора случайных запросов в инструмент, способный понимать бизнес-логику API.
Где начинаются проблемы и как их устранить
Перед началом фаззинга важно понимать, с какими трудностями можно столкнуться при подготовке, и как их избежать. Рассмотрим основные проблемы и способы их решения.
Разметка схемы и in-path параметры
Если в адресе изначально задано конкретное значение (например, /rest/user/username), RESTler будет отправлять запросы на один и тот же endpoint, так как не знает, что параметр можно менять. После ручного исправления спецификации имя пользователя становится изменяемым, и фаззер корректно мутирует его при тестировании.
Типизация параметров
Часто в спецификации не указаны точные типы данных. RESTler пытается догадаться самостоятельно, но при длительном тестировании это приводит к множеству ложных запросов и снижает эффективность. Правильная типизация позволяет мутировать только значения, сохраняя структуру параметров.
Подготовленное приложение
Фаззинг требует, чтобы тестовое приложение содержало реальные данные. Если интерфейс возвращает информацию о пользователе, которого нет в базе, RESTler получает 4xx ошибки и не понимает, какие функции можно тестировать. В этом случае можно создать тестовую спецификацию с интерфейсами добавления и удаления данных и запускать RESTlertest для подготовки базы перед фаззингом.
Парсинг JSON
Неправильно описанные JSON-структуры приводят к тому, что при каждой мутации изменяется весь объект, а не отдельные поля. Это снижает покрытие и вызывает много невалидных запросов.
Правильный вариант спецификации использует properties для каждого поля и разделение на restler_static и restler_fuzzable. Так RESTler мутирует только нужные значения, оставляя структуру целой. Это повышает качество тестирования и позволяет использовать сложные вложенные объекты.
Конвертеры
Большинство конвертеров данных работают нестабильно. Часто перед их использованием приходится маскировать информацию в спецификации, чтобы избежать ошибок компиляции и некорректных мутаций.
Ошибки при проведении фаззинга
Рассмотрим трудности, возникающие непосредственно при фаззинге и пути их решения.
Управление кодами ответов
В разных приложениях одинаковый HTTP-код может иметь разное значение. Например, 200 может содержать лог отладки, а токен авторизации иногда приходит при статусе 4xx. RESTler позволяет явно указывать, какие коды считать ошибками, с помощью параметра custom_bug_codes:
{
"custom_bug_codes":["201","203"]
}
Это помогает точнее отслеживать баги и корректно реагировать на необычные ответы сервера.
Разделение спецификации на блоки
Для повышения эффективности тестирования рекомендуется разбивать API на логические подмножества. Пример для user-rest:
GET /user/login– получение информации о пользователе;PUT /user/login– обновление данных пользователя;GET /user– список всех пользователей;POST /user– создание нового пользователя;POST /user/status– изменение статуса;POST /user/password– смена пароля.
Такой подход помогает снизить количество ложных запросов, формировать корректные цепочки запросов по функционалу и повысить производительность фаззинга.
Обработка файлов и кодировок
При тестировании API сервер может возвращать файлы с некорректным содержимым, размером или временем формирования. Ошибки также могут возникать при декодировании данных.
RESTler позволяет игнорировать ошибки декодирования с помощью параметра:
"ignore_decoding_failures": true
Для таких эндпоинтов рекомендуется увеличить таймаут ответа, чтобы фаззер корректно обрабатывал медленные или сложные ответы.
Продвинутые возможности RESTler
Посмотрим, как настраивать RESTler для работы с более сложными сценариями. В качестве тестовой среды возьмем уязвимое веб-приложение VamPI (Vulnerable API), созданное для обучения тестированию на проникновение и демонстрации основных уязвимостей из OWASP API Security Top 10). Оно воспроизводит типичную логику пользовательского сервиса: регистрация, вход в систему и работа с пользовательскими данными. После авторизации пользователь получает токен и может создавать объекты с названием и скрытым содержимым, доступными только владельцу («книги»).
Подготовка: генерация грамматики
Работа с RESTler начинается с компиляции грамматики на основе OpenAPI-спецификации:
Restler.exe compile --api_spec C:\Vampi\openapi3.yml
Аутентификация: работа с токенами
Если API требует авторизации, фаззер должен уметь работать с ней так же, как реальный клиент. В противном случае большая часть сценариев просто останется недоступной, а тестирование будет ограничено «пустыми» запросами.
RESTler поддерживает несколько способов интеграции аутентификации:
1. Токен из файла.
Проще всего использовать заранее подготовленный токен, который хранится в текстовом файле. Для этого достаточно указать путь к файлу в конфигурации engine_settings.json:
"authentication": {
"token": {
"location": "/path/to/token.txt"
}
}
Таким образом удобно проводить только быстрые проверки. Если токен имеет ограниченный срок жизни, его придется обновлять вручную.
2. Внешний скрипт
Внешний скрипт получает токен динамически. Он также настраивается через engine_settings.json:
"authentication": {
"token": {
"token_refresh_cmd": "python acquire_token.py",
"token_refresh_interval": 200
}
}
Либо параметры можно передать напрямую при запуске:
--token_refresh_command "python acquire_token.py" --token_refresh_interval 200
Этот способ позволяет автоматически обновлять токен, не прерывая процесс фаззинга, что особенно важно при длительных запусках.
3. Подключаемый модуль
В этом случае RESTler импортирует Python-файл и вызывает указанную функцию для получения токена:
"authentication": {
"token": {
"module": {
"file": "/path/to/acquire_token.py",
"function": "acquire_token_data",
"data": {
"client_id": "client_id"
}
},
"token_refresh_interval": 200
}
}
Фаззер способен передавать дополнительные параметры без изменения кода. Это удобно, если логика аутентификации сложная или требует разных конфигураций. Формат передачи должен быть единым: в первой строке указываются метаданные затем заголовки с токенами.
{u'app1': {...}, u'app2': {...}}
Authorization: Bearer <token1>
Authorization: Bearer <token2>
Для тестируемого приложения мы выбрали вариант со скриптом. Он позволяет автоматически обновлять токен и при этом не усложняет конфигурацию. Дополнительно использовались учетные записи пользователя и администратора для проверки сценариев с разными уровнями доступа.
Пример скрипта:
import requests
import json
import os
from dotenv import load_dotenv
def acquire_token(username, password):
url = "http://127.0.0.1:5000/users/v1/login"
payload = json.dumps({
"username": username,
"password": password
})
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.post(url, headers=headers, data=payload)
token = response.json()["auth_token"]
return f"Authorization: Bearer {token}"
metadata = "{u'first_token': {u'username': u'admin'}, u'second_token': {u'username': 'user1'}}"
load_dotenv()
print(metadata)
print(acquire_token(os.getenv("login1"), os.getenv("password1")))
print(acquire_token(os.getenv("login2"), os.getenv("password2")))
После успешной компиляции смотрим, сколько API-методов покрывается проверками RESTler:
Request coverage (successful / total): 6 / 6
Запуск в тестовом режиме
Когда базовая настройка завершена, RESTler запускается в тестовом режиме, при котором не менее одного раза выполняются запросы в OpenAPI и получается ответ кода состояния «200»:
restler.exe test \
--grammar_file grammar.py \
--dictionary_file dict.json \
--settings engine_settings.json
Это своего рода разведка перед основным этапом: инструмент проходит по всем эндпоинтам и проверяет, какие из них возвращают корректный ответ.
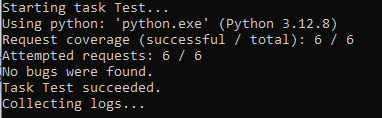
Уже здесь могут появиться первые сигналы о проблемах, например, ответы с кодом 500. RESTler автоматически сохраняет такие случаи в отдельные файлы:
Логи в этом случае играют ключевую роль. Они позволяют восстановить не только сам запрос, но и последовательность действий, которая к нему привела. Иногда именно в этой последовательности и скрывается уязвимость. Например, если сначала удалить пользователя, а затем попытаться получить связанные с ним данные, система может повести себя непредсказуемо. Подобные ошибки часто не лежат на поверхности и не всегда предусмотрены разработчиками даже в тестовых уязвимых приложениях.
Улучшение покрытия API
Если часть запросов не обрабатывается, это сигнал к тому, что спецификация требует донастройки. Для этого изучаем файл с неудачными запросами: C:\Vampi\Test\coverage_failures_to_investigate.txt.
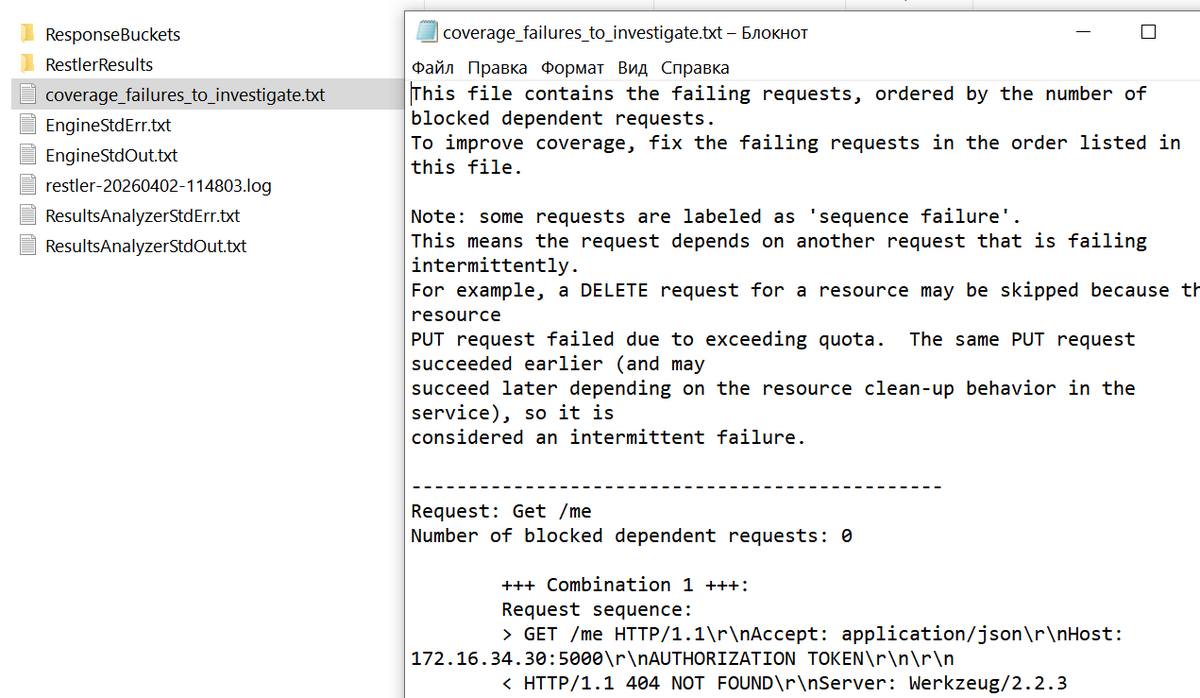
С помощью запросов Get /books/v1/{book_title} и Get /users/v1/{username} ищем книгу и пользователя, которых нет в базе. Эту проблему легко исправить, изменив примеры соответствующих запросов в спецификации API.
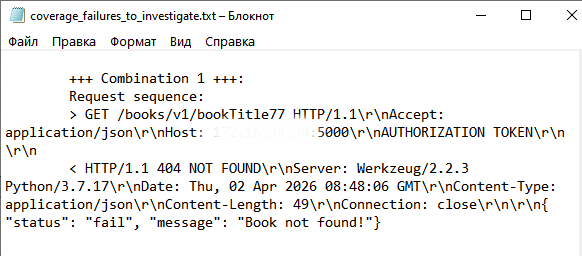
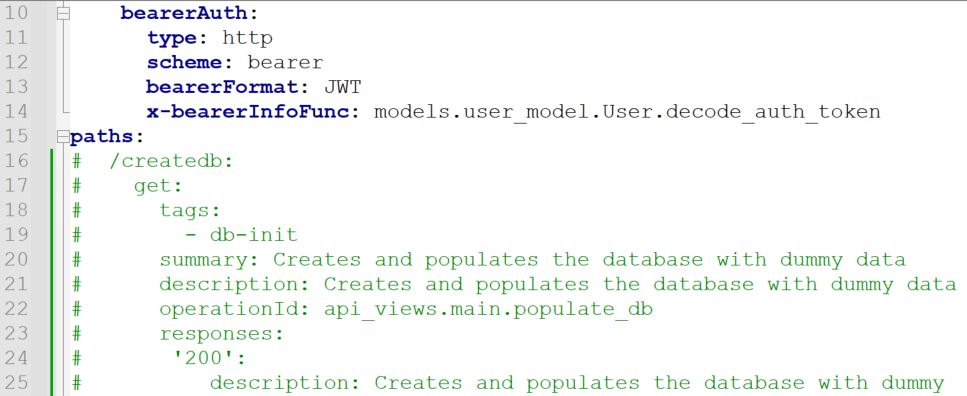
Так как уязвимость на эндпоинте уже обнаружена, запрос Get /books/v1 можно удалить из спецификации, чтобы не получать лишние срабатывания, а также убрать метод /createdb, чтобы не мешать фаззеру создавать цепочки вызовов. Получаем полное покрытие оставшихся API-методов.
Запуск фаззинга
Когда все подготовлено, можно приступать непосредственно к фаззингу. Выполняем команду:
C:\restler_bin\restler\restler.exe fuzz --grammar_file C:\Vampi\Compile\grammar.py --dictionary_file C:\Vampi\Compile\dict.json --settings C:\restler-fuzzer-main\Compile\engine_settings.json --token_refresh_interval 2 --token_refresh_command "python C:\restler-fuzzer-main\acquire_token.py" --no_ssl
После чего приложение зависает, а в логах срабатывает чекер InvalidValueChecker_timeout.
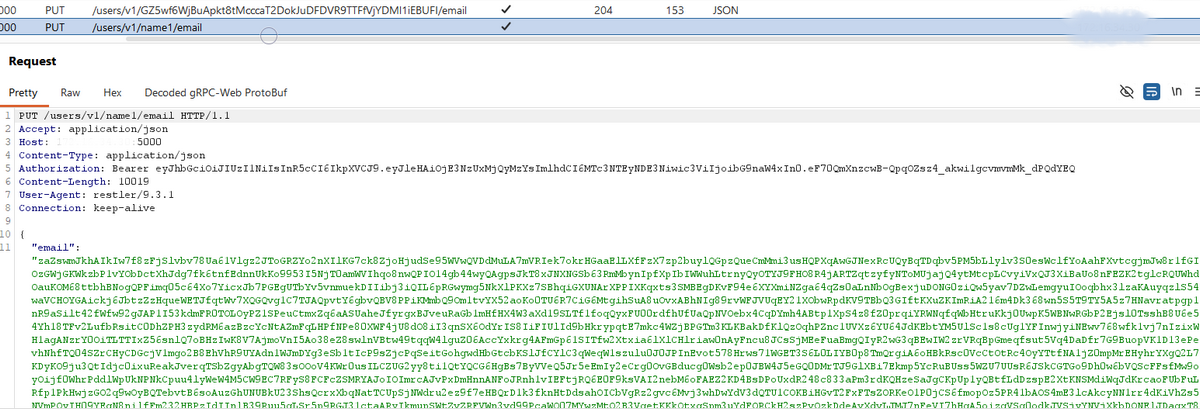
При тестировании эндпоинта /users/v1/{username}/email было обнаружено зависание сервиса при передаче в параметр email большого объема данных.
Причина оказалась в некорректно реализованном регулярном выражении, используемом для валидации почты. При обработке специально сформированной строки с большим числом возможных вариантов сопоставления приложение тратило значительное время на вычисления.
Это классический сценарий атаки типа Regex DoS (Regular Expression Denial of Service), при которой злоумышленник может перегрузить сервис за счет сложных входных данных. В результате ресурсы приложения расходуются неэффективно, что может привести к отказу в обслуживании для других пользователей.
С точки зрения классификации уязвимостей, данный случай относится к категории API4:2023 Unrestricted Resource Consumption.
Чтобы продолжить фаззинг и избежать повторного возникновения этой проблемы, скорректируем грамматику (grammar.py), исключив поле email из мутаций.
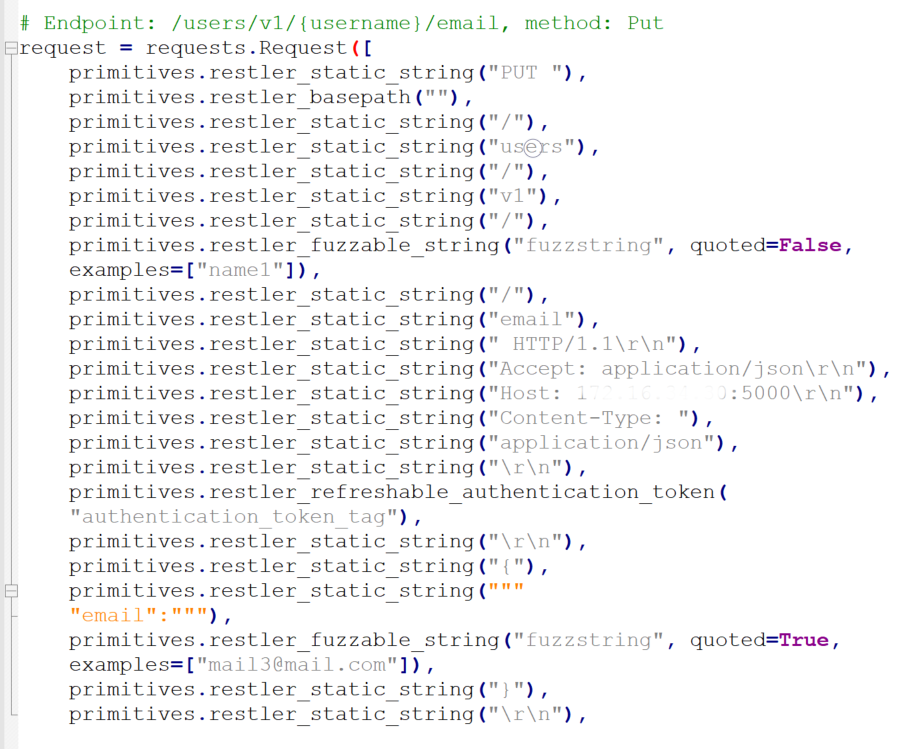
На следующем прогоне сработал чекер InvalidValueChecker, подставляющий в параметры заведомо некорректные значения. При необходимости набор таких значений можно расширить через словарь или генератор, чтобы сделать проверки более точечными.
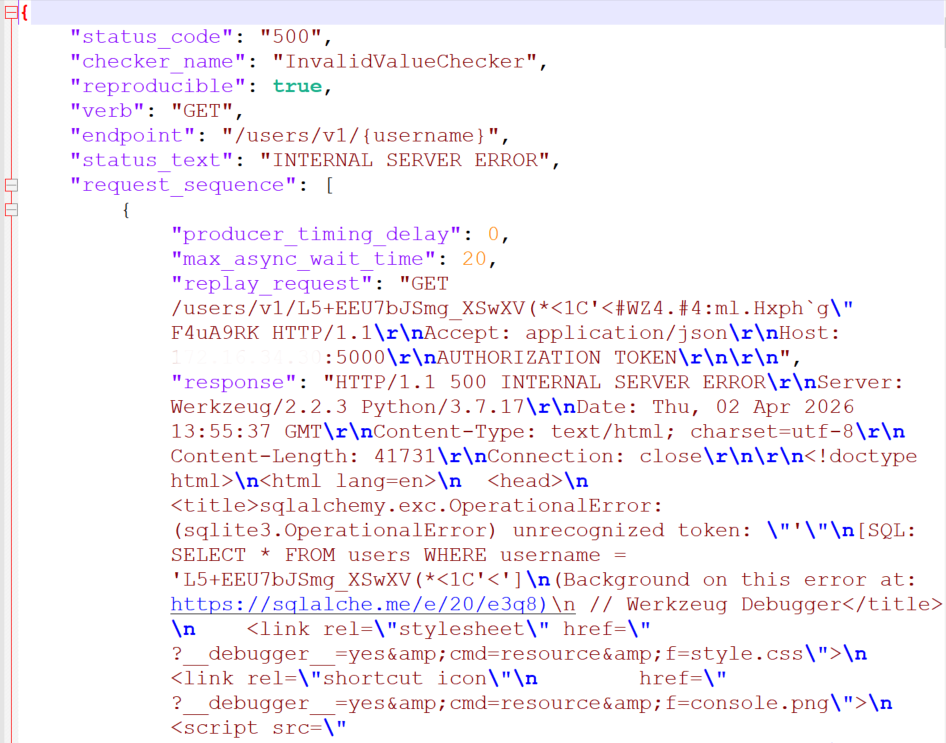
При обращении к эндпоинту /users/v1/{username} с подставленным сгенерированным значением имени пользователя сервер вернул внутреннюю ошибку. В ответе оказался traceback с фрагментом SQL-запроса, что является признаком утечки служебной информации и потенциальной SQL-инъекции. Подобное поведение относится к категории API8:2023 Security Misconfiguration.
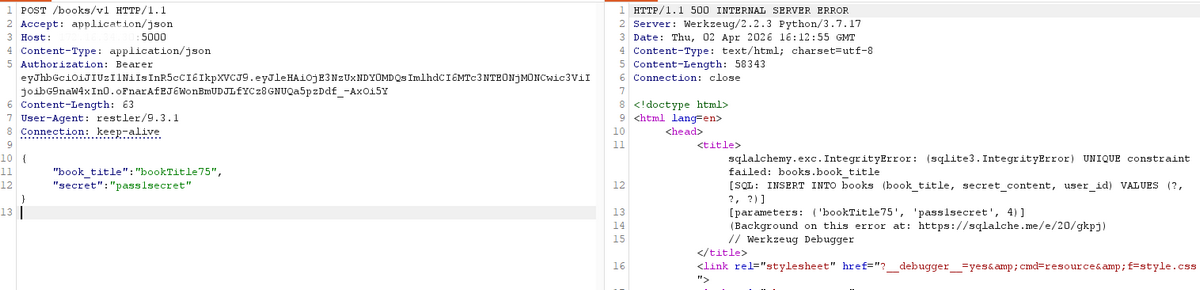
Аналогичная внутренняя ошибка была зафиксирована и при обращении к /books/v1, что дополнительно указывает на проблемы в обработке запросов на стороне сервера.
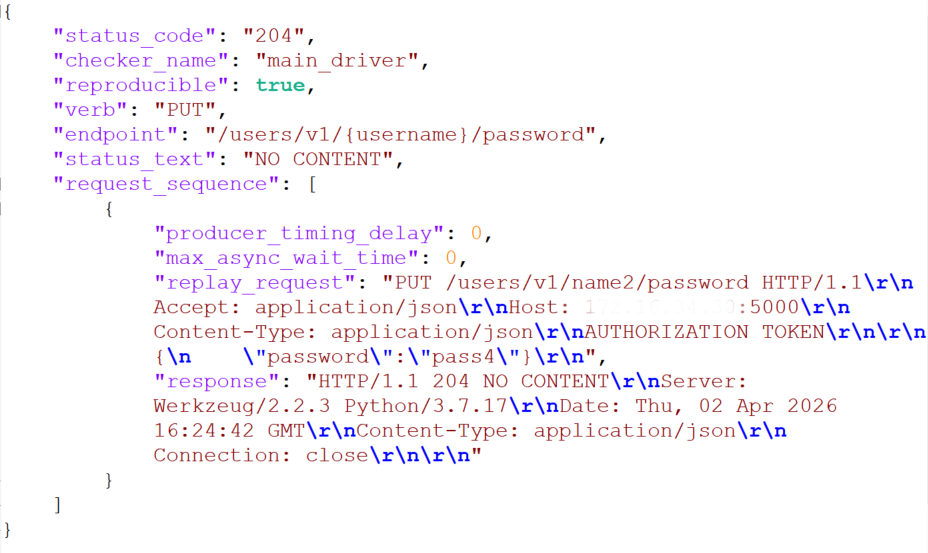
Фаззер умеет отмечать баги не только ответы с кодом «500», но и любые другие. Для этого в Engine_settings задаются параметры custom_bug_codes (список кодов, считающихся ошибками) или custom_non_bug_codes (коды, которые игнорируются). В нашем примере RESTler настроен так, чтобы отслеживались ответы с кодом «200» для эндпоинта /users/v1/{username}/password. Параметр include_requests позволяет ограничить тестирование только выбранными методами, фильтруя остальные запросы из грамматики.

Такой подход позволяет проверить, может ли обычный пользователь изменить пароль другого. В ходе следующей итерации фаззинга в файле с багами main_driver_20x_1.json был зафиксирован успешный запрос на смену пароля пользователя name2, несмотря на то, что фаззер авторизовался только под обычным пользователем name1.
Результаты
В ходе фаззинга были найдены 4 подтвержденных бага, 3 из которых приводят к уязвимостям. Это показывает, что инструмент способен выявлять ошибки, приводящие к серьезным проблемам API, таким как Excessive Data Exposure, Injection, Unrestricted Resource Consumption и Broken User Authentication.
Итоги
RESTler показывает себя как мощный инструмент для комплексного анализа REST API, но эффективность фаззинга напрямую зависит от качества подготовки и настройки инструмента.
Использование грамматического фаззинга вместе с генерацией запросов на основе обратной связи позволяет лучше понимать логику работы API и выявлять уязвимости, которые трудно найти вручную.
Дополнительно, RESTler позволяет интегрировать модульное и нагрузочное тестирование, исследовать производительность и устойчивость к высоким нагрузкам. В результате применение инструмента помогает системно повышать качество тестирования, минимизировать риски критических ошибок и обеспечивать надежную работу веб-сервисов в реальных условиях.